What’s New from v0.8.0 to v0.12.0¶
We are excited to present pyribs 0.12.0! Compared to 0.8.0, the past few releases of pyribs have introduced algorithms and features intended to make the library more flexible than ever! This release supports Python 3.10 and up, with Python 3.9 being dropped due to being end-of-life.
New Algorithms¶
Pyribs now supports the following algorithms!
Discount Model Search (DMS) (Tjanaka 2026) is now supported with the introduction of the
DiscountArchiveandDiscountModelManager. We include an example of how to run DMS in Sphere Function with Various Algorithms, with more examples available in the DMS repository.We have begun adding support for Dominated Novelty Search (DNS) (Bahlous-Boldi 2025) through the addition of the
DNSArchive.Thanks to @ryanboldi for contributing this implementation in #664!
Novelty Search with Local Competition (NSLC) is now supported via the
NSLCRankerandNSLCClassicRanker. An example of how to run NSLC is available in Sphere Function with Various Algorithms.Thanks to @efsiatras for contributing this implementation in #690!
Novelty Search with Threshold Decay:
ProximityArchivenow includes support for automatically decaying thenovelty_thresholdacross iterations.Thanks to Alejandro Marrero for implementing this in #709!
Density Descent Search with Continuous Normalizing Flows (DDS-CNF) is now supported in the
DensityArchive. An example of how to run DDS-CNF is available in Sphere Function with Various Algorithms.Thanks again to @efsiatras for contributing this implementation in #691!
The Supported Algorithms page includes a list of algorithms supported in pyribs.
New Visualizations¶
We introduce new functions for plotting the distribution of objective values in one or more archives:
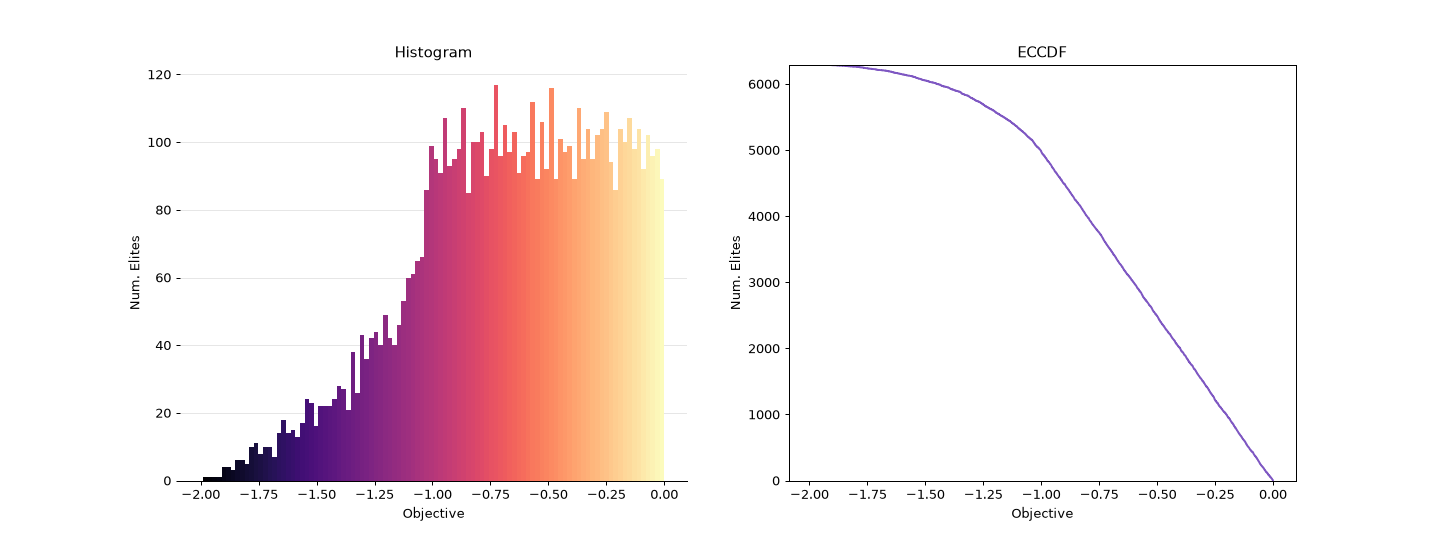
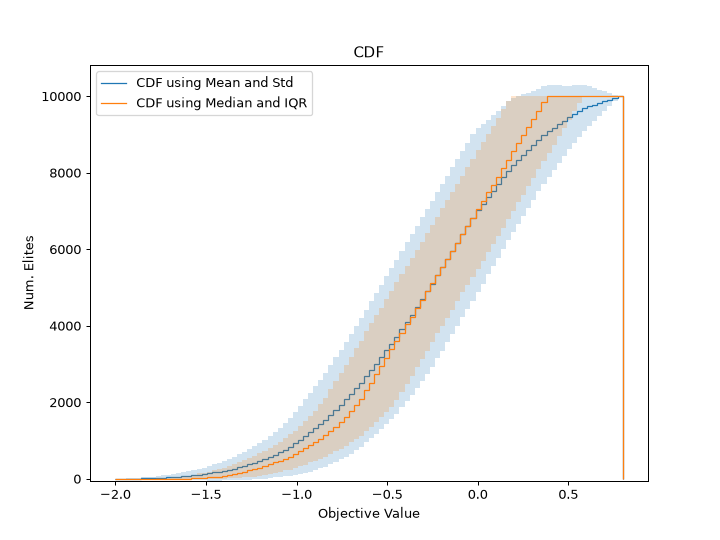
ribs.visualize.archive_histogram()plots the histogram of objective values in a single archive. It has a similar purpose to heatmap functions, in that it is intended to operate on just one archive at a time.ribs.visualize.archive_ecdf()plots the empirical cumulative distribution function (ECDF) of objective values in a single archive.ribs.visualize.aggregate_cdf()plots the CDF or CCDF of objective values, aggregated over multiple archives. This is useful for understanding how well a QD algorithm performs across multiple runs.
Below are examples of these three functions – in particular, the histogram bars are colored based on their objective value!
"""Demonstration of archive_histogram and archive_ecdf."""
import numpy as np
import matplotlib.pyplot as plt
from ribs.archives import GridArchive
from ribs.visualize import archive_histogram, archive_ecdf
# Populate the archive with the negative sphere function.
archive = GridArchive(solution_dim=2,
dims=[100, 100],
ranges=[(-1, 1), (-1, 1)])
x = np.random.uniform(-1, 1, 10000)
y = np.random.uniform(-1, 1, 10000)
archive.add(solution=np.stack((x, y), axis=1),
objective=-(x**2 + y**2),
measures=np.stack((x, y), axis=1))
# Plot a histogram and ECCDF of the archive.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16,6))
archive_histogram(archive, ax=ax1, cmap="magma")
ax1.set(title="Histogram", xlabel="Objective", ylabel="Num. Elites")
archive_ecdf(archive, ax=ax2, complementary=True, stat="count", color="#7e57c2")
ax2.set(title="ECCDF", xlabel="Objective", ylabel="Num. Elites")
plt.show()
"""Demonstration of aggregate_cdf."""
import numpy as np
import matplotlib.pyplot as plt
from ribs.archives import GridArchive
from ribs.visualize import aggregate_cdf
# Populate 5 archives with slightly offset versions of the negative sphere
# function.
archives = []
for i in range(5):
archive = GridArchive(
solution_dim=2, ranges=[(-1, 1), (-1, 1)], dims=[100, 100]
)
xxs, yys = np.meshgrid(np.linspace(-1, 1, 100), np.linspace(-1, 1, 100))
xxs, yys = xxs.ravel(), yys.ravel()
coords = np.stack((xxs, yys), axis=1)
archive.add(
solution=coords,
objective=-(xxs**2 + yys**2) + 0.2 * i, # Negative sphere, with offset.
measures=coords,
)
archives.append(archive)
plt.figure(figsize=(8, 6))
line, _ = aggregate_cdf(archives, cumulative=True)
line.set_label("CDF using Mean and Std")
line, _ = aggregate_cdf(archives, cumulative=True, estimator="median", errorbar="iqr")
line.set_label("CDF using Median and IQR")
plt.title("CDF")
plt.xlabel("Objective Value")
plt.ylabel("Num. Elites")
plt.legend()
🐛 Bug Fixes¶
#704 fixed a bug that occurred when using
ProximityArchivewith local competition. In short, if there were solutions that were novel enough to be added to the archive, then solutions that were not novel enough could be added despite being low-performing. In this case, the solutions that are not novel enough should only be added if they outperform their nearest neighbor in the archive. Thanks @zibasPk for identifying and fixing this bug!
Overhauling CVTArchive¶
We introduce a number of new features and (unfortunately) breaking changes to
CVTArchive. For most users, it should suffice to know
that an initialization of CVTArchive that once looked like this:
from ribs.archives import CVTArchive
archive = CVTArchive(
solution_dim=12,
cells=10000,
ranges=[(-1, 1), (-1, 1)],
use_kd_tree=True,
)
Now looks like this. Note that cells has been replaced with centroids, and
use_kd_tree has been replaced with nearest_neighbors.
from ribs.archives import CVTArchive
archive = CVTArchive(
solution_dim=12,
centroids=10000,
ranges=[(-1, 1), (-1, 1)],
nearest_neighbors="scipy_kd_tree",
)
Our new tutorial serves as a starting point for using the new archive: Specifying Centroids for CVTArchive.
Detailed Changes¶
Below we provide further details on the changes, with even more detail available in #621.
Centroid generation has been moved out of CVTArchive. In the past, CVTArchive contained methods for generating centroids that could be specified via the
centroid_methodparameter. However, centroid generation is extremely customizable, and we believe it should be left to the user rather than handled in the archive initialization itself. As such, we have removed thecentroid_methodparameter as well as these centroid generation methods, and we have instead added a new tutorial that shows different options for specifying and generating centroids: Specifying Centroids for CVTArchive.In a similar vein, it is now possible to generate centroids with the
k_means_centroids()function, which samples points in a measure space and performs k-means clustering to identify the centroids. This function, as well as other workflows with centroids, are included in the above tutorial.Finally, since we have separated centroid generation from CVTArchive, the
samplesproperty is now deprecated, as is theplot_samplesparameter incvt_archive_heatmap()andcvt_archive_3d_plot().cellsandcustom_centroidsare now replaced with thecentroidsparameter. We found thatcellsandcustom_centroidswere redundant with each other. Instead, the newcentroidsparameter can either be an int indicating the number of cells in the archive, or an array-like with the coordinates of the centroids. This supports the separation of centroid generation from CVTArchive by making it easier to specify centroids. Previously, bothcellsandcustom_centroidshad to be specified to use centroids created by the user, but now, onlycentroidsis needed.Nearest-neighbor lookup is now more flexible. Previously, we only supported two methods for nearest-neighbor lookup, via brute-force and via scipy’s
KDTree. To support more methods, we have deprecated theuse_kd_treeparameter and replaced it with a newnearest_neighborsparameter. Thisnearest_neighborsparameter can be set to"scipy_kd_tree","brute_force", or the newest option,"sklearn_nn", which uses scikit-learn’sNearestNeighbors.Correspondingly, we have added
sklearn_nn_kwargsandkdtree_query_kwargs, which allow specifying more options to the internal objects used for nearest-neighbor search.
New dtype Specifications for Archives¶
Previously, we found specifying separate dtypes for the solution, objective, and
measures in an archive to be complicated due to requiring passing a dict.
Instead, we now allow passing in individual dtypes: solution_dtype,
objective_dtype, and measures_dtype. It is also still possible to pass in
dtype to set all of these at once, but dtype can no longer be a dict. For
example, the following sets the solutions to be objects, while the objective and
measures are float32:
import numpy as np
from ribs.archives import GridArchive
archive = GridArchive(
solution_dim=(),
dims=[20, 20],
ranges=[(1, 10), (1, 10)],
solution_dtype=object,
objective_dtype=np.float32,
measures_dtype=np.float32,
)
(This example is taken from the tutorial Orchestrating LLMs to Write Diverse Stories with Quality Diversity through AI Feedback.) For more info, see #639, #643, and #661.
Multi-Dimensional Solutions in Emitters¶
This release improves support for multi-dimensional solutions in emitters. In
particular, the GaussianEmitter and
IsoLineEmitter can now generate multi-dimensional
solutions (#650). In a similar vein, it is now possible to specify the
bounds of the solution space in emitters via lower_bounds and upper_bounds
(#649, #657). The original bounds parameter is still supported but
cannot be used at the same time. Thus, the following creates a GaussianEmitter
that generates solutions of shape (5, 5) bounded by -1.0 and 1.0 in each
dimension:
import numpy as np
from ribs.archives import GridArchive
from ribs.emitters import GaussianEmitter
archive = GridArchive(
solution_dim=(5, 5),
dims=[20, 20],
ranges=[(-2, 2), (-2, 2)],
)
emitters = [
GaussianEmitter(
archive,
sigma=0.1,
x0=np.zeros((5, 5)),
lower_bounds=np.full((5, 5), -1.0),
upper_bounds=np.full((5, 5), 1.0),
batch_size=64,
)
]
🚨 Additional Breaking Changes¶
In
CVTArchiveandProximityArchive,ckdtree_kwargsis now referred to askdtree_kwargs, as we have stopped using scipy’s cKDTree in favor of KDTree (#676)In
ArrayStore,as_raw_dictandfrom_raw_dicthave been removed as they were not being used (#575)
✨ Additional Features¶
In the archives,
data()now returns an object of the corresponding type whenfieldsis a single str andreturn_type="dict"|"tuple"|"pandas"(#721)In the archives,
sample_elites()now supports thereplaceparameter to indicate whether elites should be replaced when sampling (#682)parallel_axes_plot()now supports plottingProximityArchive(#647)ArrayStorenow supports backends such as torch and cupy, drawing from the Python array API standard (#570, #645)Logging, outputs, and metrics have been updated in the examples (#694). For example, the Sphere example (Sphere Function with Various Algorithms) now has more flexible output directories, and it also uses loguru for logging.
Developer Workflow¶
Finally, in addition to the above library improvements, we have migrated from using yapf and pylint to using ruff and pylint for formatting, linting, and type checking.
Past Editions¶
Past editions of “What’s New” are available below.