ribs.archives.CVTArchive¶
-
class ribs.archives.CVTArchive(*, solution_dim: Int | tuple[Int, ...], centroids: Int | ArrayLike | str | Path, ranges: Collection[tuple[Float, Float]], learning_rate: Float | None =
None, threshold_min: Float =-inf, qd_score_offset: Float =0.0, seed: Int | None =None, solution_dtype: DTypeLike =None, objective_dtype: DTypeLike =None, measures_dtype: DTypeLike =None, dtype: DTypeLike =None, extra_fields: FieldDesc | None =None, samples: Int | ArrayLike =100000, k_means_kwargs: dict | None =None, nearest_neighbors: 'scipy_kd_tree' | 'brute_force' | 'sklearn_nn' ='scipy_kd_tree', kdtree_kwargs: dict | None =None, kdtree_query_kwargs: dict | None =None, chunk_size: Int =None, sklearn_nn_kwargs: dict | None =None, cells: None =None, custom_centroids: None =None, centroid_method: None =None, use_kd_tree: None =None, ckdtree_kwargs: None =None)[source]¶ An archive that tessellates the measure space with centroids.
This archive originates in Vassiliades 2018. It uses a Centroidal Voronoi Tessellation (CVT) to divide an n-dimensional measure space into k cells. Each cell is represented by a centroid, and when items are inserted into the archive, we identify their cell by finding the closest centroid in measure space.
Several options are available for creating the centroids used in the CVT. The default option in this archive is to sample points uniformly in the measure space and then cluster them using k-means clustering; the centroids of the clusters are then used as the centroids of the CVT in this archive. This procedure is implemented in
ribs.archives.k_means_centroids(), which internally callssklearn.cluster.k_means()to perform the clustering. For more on specifying centroids, refer to the tutorial Specifying Centroids for CVTArchive.If running multiple experiments with this archive, it may be useful to maintain the same centroids across experiments. To do this, we recommend generating the centroids just once, such as by calling
ribs.archives.k_means_centroids(). Then, save the centroids to a file (e.g., withnumpy.save()). When constructing the archive for new experiments, the centroids can be loaded from the file and passed to the archive via thecentroidsparameter. More information is available in the aforementioned tutorial.Several options are also available for finding the closest centroid in measure space; these are set via the
nearest_neighborsparameter:nearest_neighbors="scipy_kd_tree"is the default option. It usesscipy.spatial.KDTreeto find the nearest neighbors in terms of Euclidean distance in O(log(number of cells)) time.nearest_neighbors="brute_force"also uses Euclidean distance but operates in O(number of cells) time.nearest_neighbors="sklearn_nn"usessklearn.neighbors.NearestNeighborsto find the nearest neighbors.
Note
To compare the performance of the different nearest neighbor methods, we ran benchmarks where we inserted 1k batches of 100 solutions into a 2D archive with varying numbers of cells. We took the minimum over 5 runs for each data point — minimum is recommended in the docs for
timeit.Timer.repeat(). Note the logarithmic scales. This plot was generated on a reasonably modern laptop; see benchmarks/cvt_add.py in the project repo for more information.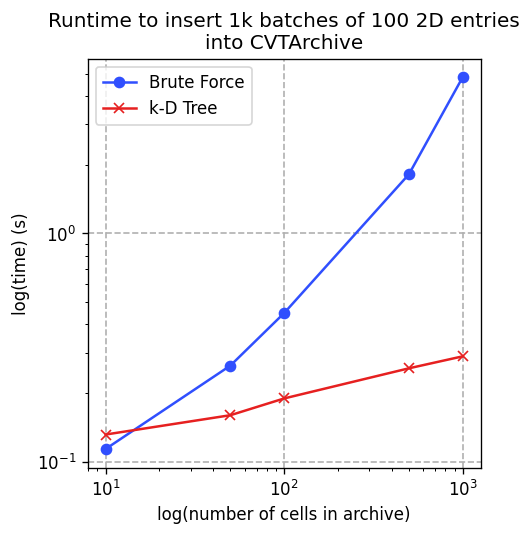
We hope that the performance differences in this plot serve as a rough guide for choosing nearest neighbor methods, but we note that they are not definitive, as each nearest neighbor method has a wide variety of options that can influence performance. Furthermore, performance is vastly affected by factors like the dimensionality of the measure space and the number of centroids/cells.
Note
The idea of archive thresholds was introduced in Fontaine 2023. For more info on thresholds, including the
learning_rateandthreshold_minparameters, refer to our tutorial Upgrading CMA-ME to CMA-MAE on the Sphere Benchmark.- Parameters:¶
- solution_dim: Int | tuple[Int, ...]¶
Dimensionality of the solution space. Scalar or multi-dimensional solution shapes are allowed by passing an empty tuple or tuple of integers, respectively.
- centroids: Int | ArrayLike | str | Path¶
This parameter may be an integer, which indicates the number of centroids in the CVT. In this case, the centroids will be automatically generated with
ribs.archives.k_means_centroids(). Alternatively, this parameter can be a (num_centroids, measure_dim) array with the measure space coordinates of the centroids. Finally, this parameter can specify a file holding the centroids; this file will be read withnumpy.load().- ranges: Collection[tuple[Float, Float]]¶
Upper and lower bound of each dimension of the measure space, e.g.
[(-1, 1), (-2, 2)]indicates the first dimension should have bounds \([-1,1]\) (inclusive), and the second dimension should have bounds \([-2,2]\) (inclusive).rangesshould be the same length asdims.- learning_rate: Float | None =
None¶ The learning rate for threshold updates. Defaults to 1.0.
- threshold_min: Float =
-inf¶ The initial threshold value for all the cells.
- qd_score_offset: Float =
0.0¶ Archives often contain negative objective values, and if the QD score were to be computed with these negative objectives, the algorithm would be penalized for adding new cells with negative objectives. Thus, a standard practice is to normalize all the objectives so that they are non-negative by introducing an offset. This QD score offset will be subtracted from all objectives in the archive, e.g., if your objectives go as low as -300, pass in -300 so that each objective will be transformed as
objective - (-300).- seed: Int | None =
None¶ Value to seed the random number generator. Set to None to avoid a fixed seed.
- solution_dtype: DTypeLike =
None¶ Data type of the solutions. Defaults to float64 (numpy’s default floating point type).
- objective_dtype: DTypeLike =
None¶ Data type of the objectives. Defaults to float64 (numpy’s default floating point type).
- measures_dtype: DTypeLike =
None¶ Data type of the measures. Defaults to float64 (numpy’s default floating point type).
- dtype: DTypeLike =
None¶ Shortcut for providing data type of the solutions, objectives, and measures. Defaults to float64 (numpy’s default floating point type). This parameter sets all the dtypes simultaneously. To set individual dtypes, pass
solution_dtype,objective_dtype, andmeasures_dtype. Note thatdtypecannot be used at the same time as those parameters.- extra_fields: FieldDesc | None =
None¶ Description of extra fields of data that are stored next to elite data like solutions and objectives. The description is a dict mapping from a field name (str) to a tuple of
(shape, dtype). For instance,{"foo": ((), np.float32), "bar": ((10,), np.float32)}will create a “foo” field that contains scalar values and a “bar” field that contains 10D values. Note that field names must be valid Python identifiers, and names already used in the archive are not allowed.- samples: Int | ArrayLike =
100000¶ For convenience, this argument is passed directly to
k_means_centroids()(assuming that function is called).- k_means_kwargs: dict | None =
None¶ For convenience, this argument is passed directly to
k_means_centroids()(assuming that function is called).- nearest_neighbors: 'scipy_kd_tree' | 'brute_force' | 'sklearn_nn' =
'scipy_kd_tree'¶ Method to use for computing nearest neighbors. See earlier in this docstring for more info.
- kdtree_kwargs: dict | None =
None¶ kwargs for
scipy.spatial.KDTree. By default, we do not pass in any kwargs. Only applicable whennearest_neighbors="scipy_kd_tree".- kdtree_query_kwargs: dict | None =
None¶ kwargs for
scipy.spatial.KDTree.query(), which is called when identifying nearest neighbors. By default, we do not pass in any kwargs. Only applicable whennearest_neighbors="scipy_kd_tree".- chunk_size: Int =
None¶ If passed, brute forcing the closest centroid search will chunk the distance calculations to compute chunk_size inputs at a time. Only applicable when
nearest_neighbors="brute_force".- sklearn_nn_kwargs: dict | None =
None¶ kwargs for
sklearn.neighbors.NearestNeighbors. By default, we do not pass in any kwargs. Only applicable whennearest_neighbors="sklearn_nn".- cells: None =
None¶ DEPRECATED.
- custom_centroids: None =
None¶ DEPRECATED.
- centroid_method: None =
None¶ DEPRECATED.
- use_kd_tree: None =
None¶ DEPRECATED.
- Raises:¶
ValueError – Invalid values for learning_rate and threshold_min.
ValueError – Invalid names in extra_fields.
ValueError –
centroidshas the wrong shape.ValueError – nearest_neighbors has an invalid value.
Methods
__iter__()Creates an iterator over the elites in the archive.
__len__()Number of elites in the archive.
add(solution, objective, measures, **fields)Inserts a batch of solutions into the archive.
add_single(solution, objective, measures, ...)Inserts a single solution into the archive.
clear()Removes all elites in the archive.
data()Returns data of the elites in the archive.
index_of(measures)Finds indices of the centroids closest to the given measures.
index_of_single(measures)Returns the index of the measures for one solution.
retrieve(measures)Queries the archive for elites with the given batch of measures.
retrieve_single(measures)Queries the archive for an elite with the given measures.
sample_elites(n[, replace])Randomly samples elites from the archive.
Attributes
The elite with the highest objective in the archive.
Total number of cells in the archive.
(num_centroids, measure_dim) array of centroids used in the CVT.
Mapping from field name to dtype for all fields in the archive.
Whether the archive is empty.
List of data fields in the archive.
(
measure_dim,) array listing the size of each dim (upper_bounds - lower_bounds).The learning rate for threshold updates.
(
measure_dim,) array listing the lower bound of each dimension.Dimensionality of the measure space.
Dimensionality of the objective space.
Subtracted from objective values when computing the QD score.
DEPRECATED.
Dimensionality of the solution space.
Statistics about the archive.
The initial threshold value for all the cells.
(
measure_dim,) array listing the upper bound of each dimension.- add(solution: numpy.typing.ArrayLike, objective: numpy.typing.ArrayLike, measures: numpy.typing.ArrayLike, **fields: numpy.typing.ArrayLike) dict[str, ndarray][source]¶
Inserts a batch of solutions into the archive.
Each solution is only inserted if it has a higher
objectivethan the threshold of the corresponding cell. For the default values oflearning_rateandthreshold_min, this threshold is simply the objective value of the elite previously in the cell. If multiple solutions in the batch end up in the same cell, we only insert the solution with the highest objective. If multiple solutions end up in the same cell and tie for the highest objective, we insert the solution that appears first in the batch.For the default values of
learning_rateandthreshold_min, the threshold for each cell is updated by taking the maximum objective value among all the solutions that landed in the cell, resulting in the same behavior as in the vanilla MAP-Elites archive. However, for other settings, the threshold is updated with the batch update rule described in the appendix of Fontaine 2023.Note
The indices of all arguments should “correspond” to each other, i.e.,
solution[i],objective[i], andmeasures[i]should be the solution parameters, objective, and measures for solutioni.- Parameters:¶
- solution: numpy.typing.ArrayLike¶
(batch_size,
solution_dim) array of solution parameters.- objective: numpy.typing.ArrayLike¶
(batch_size,) array with objective function evaluations of the solutions.
- measures: numpy.typing.ArrayLike¶
(batch_size,
measure_dim) array with measure space coordinates of all the solutions.- **fields: numpy.typing.ArrayLike¶
Additional data for each solution. Each argument should be an array with batch_size as the first dimension.
- Returns:¶
Information describing the result of the add operation. The dict contains the following keys:
"status"(numpy.ndarrayofnumpy.int32): An array of integers that represent the “status” obtained when attempting to insert each solution in the batch. Each item has the following possible values:0: The solution was not added to the archive.1: The solution improved the objective value of a cell which was already in the archive.2: The solution discovered a new cell in the archive.
All statuses (and values, below) are computed with respect to the current archive. For example, if two solutions both introduce the same new archive cell, then both will be marked with
2.The alternative is to depend on the order of the solutions in the batch – for example, if we have two solutions
aandbthat introduce the same new cell in the archive,acould be inserted first with status2, andbcould be inserted second with status1because it improves upona. However, our implementation does not do this.To convert statuses to a more semantic format, cast all statuses to
AddStatus, e.g., with[AddStatus(s) for s in add_info["status"]]."value"(numpy.ndarrayofdtypes[“objective”]): An array with values for each solution in the batch. With the default values oflearning_rate = 1.0andthreshold_min = -np.inf, the meaning of each value depends on the correspondingstatusand is identical to that in CMA-ME (Fontaine 2020):0(not added): The value is the “negative improvement,” i.e., the objective of the solution passed in minus the objective of the elite still in the archive (this value is negative because the solution did not have a high enough objective to be added to the archive).1(improve existing cell): The value is the “improvement,” i.e., the objective of the solution passed in minus the objective of the elite previously in the archive.2(new cell): The value is just the objective of the solution.
In contrast, for other values of
learning_rateandthreshold_min, each value is equivalent to the objective value of the solution minus the threshold of its corresponding cell in the archive.
- Raises:¶
ValueError – The array arguments do not match their specified shapes.
ValueError –
objectiveormeasureshas non-finite values (inf or NaN).
- add_single(solution: numpy.typing.ArrayLike, objective: numpy.typing.ArrayLike, measures: numpy.typing.ArrayLike, **fields: numpy.typing.ArrayLike) dict[str, Any][source]¶
Inserts a single solution into the archive.
The solution is only inserted if it has a higher
objectivethan the threshold of the corresponding cell. For the default values oflearning_rateandthreshold_min, this threshold is simply the objective value of the elite previously in the cell. The threshold is also updated if the solution was inserted.Note
This method is provided as an easier-to-understand implementation that has less performance due to inserting only one solution at a time. For better performance, see
add().- Parameters:¶
- Returns:¶
Information describing the result of the add operation. The dict contains
statusandvaluekeys; refer toadd()for the meaning of status and value.- Raises:¶
ValueError – The array arguments do not match their specified shapes.
ValueError –
objectiveis non-finite (inf or NaN) ormeasureshas non-finite values.
-
data(fields: str, return_type: None =
None) ndarray[source]¶ -
data(fields: None | Collection[str] =
None, return_type: None =None) dict[str, ndarray] -
data(fields: None | Collection[str] | str =
None, return_type: 'dict' ='dict') dict[str, ndarray] -
data(fields: None | Collection[str] | str =
None, return_type: 'tuple' ='tuple') tuple[ndarray] -
data(fields: None | Collection[str] | str =
None, return_type: 'pandas' ='pandas') ArchiveDataFrame Returns data of the elites in the archive.
Changed in version 0.12.0: When
fieldsis a single str andreturn_typeis “dict”, “tuple”, or “pandas”, we now return a dict, tuple, or ArchiveDataFrame with only that field. Previously,return_typewas ignored in that case. Furthermore, the default ofreturn_typeis now None, and it is set depending on the type offields. See #721 for more info.- Parameters:¶
- fields: str¶
- fields: None | Collection[str] =
None - fields: None | Collection[str] | str =
None List of fields to include, such as
"solution","objective","measures", and other fields in the archive. This can also be a single str indicating a field name. The default of None indicates that all fields in the archive should be included.- return_type: None =
None¶ - return_type: 'dict' =
'dict' - return_type: 'tuple' =
'tuple' - return_type: 'pandas' =
'pandas' Data to return; see below. If
fieldsis a str and this is None, a single array is returned. Iffieldsis a collection of str or None, then this defaults to “dict”.
- Returns:¶
The data for all elites in the archive. All data returned by this method will be a copy, i.e., the data will not update as the archive changes. If
fieldsis a single str andreturn_typeis None, the returned data will just be an array holding data for the given field, such as:measures = archive.data("measures")Otherwise, the returned data can take the following forms, depending on the
return_typeargument:return_type="dict"orreturn_type=None: Dict mapping from the field name to the field data at the given indices. The keys in this dict can be modified with thefieldsarg; duplicate fields will be ignored since the dict stores unique keys. This is the default return type whenfieldsis None or a collection of str. Some examples:# Both of these retrieve all data in the archive. data = archive.data() # fields=None, return_type=None data = archive.data(return_type="dict") # fields=None # { # "solution": [[1.0, 1.0, ...], ...], # "objective": [1.5, ...], # "measures": [[1.0, 2.0], ...], # ... # } # Both of these only retrieve the specified fields. data = archive.data(["objective", "measures"]) # return_type=None data = archive.data(["objective", "measures"], return_type="dict") # { # "objective": [1.5, ...], # "measures": [[1.0, 2.0], ...], # } # Both of these retrieve only a single field. data = archive.data("measures", return_type="dict") data = archive.data(["measures"], return_type="dict") # { # "measures": [[1.0, 2.0], ...], # }return_type="tuple": Tuple of arrays matching the field order infields. Some examples with unpacking:solutions, objectives, measures = archive.data(return_type="tuple") # fields=None objectives, measures = archive.data(["objective", "measures"], return_type="tuple") (solutions,) = archive.data("solution", return_type="tuple")Unlike with the
dictreturn type, duplicate fields will show up as duplicate entries in the tuple, e.g.,fields=["objective", "objective"]will result in two objective arrays being returned.When
fields=None(the default case), the fields in the tuple will be ordered according to thefield_list.return_type="pandas": AnArchiveDataFramewith the following columns:For fields that are scalars, a single column with the field name. For example,
objectivewould have a single column calledobjective.For fields that are 1D arrays, multiple columns with the name suffixed by its index. To illustrate, for a
measuresfield of length 10, the dataframe would contain 10 columns with namesmeasures_0,measures_1, …,measures_9. The output format for fields with >1D data is currently not defined.
In short, the dataframe might look like this by default:
solution_0
…
objective
measures_0
…
…
…
Like the other return types, the columns returned can be adjusted with the
fieldsparameter.
- Raises:¶
ValueError – Invalid field name provided.
ValueError – Invalid return_type provided.
ValueError – Passed
return_type="pandas"when one of the fields has >1D data.
- index_of(measures: numpy.typing.ArrayLike) ndarray[source]¶
Finds indices of the centroids closest to the given measures.
If
index_batchis the batch of indices returned by this method, thenarchive.centroids[index_batch[i]]holds the coordinates of the centroid closest tomeasures[i]. Seecentroidsfor more info.The centroid indices are located using the method specified by
nearest_neighborsduring initialization.- Parameters:¶
- measures: numpy.typing.ArrayLike¶
(batch_size,
measure_dim) array of coordinates in measure space.
- Returns:¶
(batch_size,) array of centroid indices corresponding to each measure space coordinate.
- Raises:¶
ValueError –
measuresis not of shape (batch_size,measure_dim).ValueError –
measureshas non-finite values (inf or NaN).
- index_of_single(measures: numpy.typing.ArrayLike) int | integer[source]¶
Returns the index of the measures for one solution.
See
index_of().- Parameters:¶
- measures: numpy.typing.ArrayLike¶
(
measure_dim,) array of measures for a single solution.
- Returns:¶
Integer index of the measures in the archive’s storage arrays.
- Raises:¶
ValueError –
measuresis not of shape (measure_dim,).ValueError –
measureshas non-finite values (inf or NaN).
- retrieve(measures: numpy.typing.ArrayLike) tuple[ndarray, dict[str, ndarray]][source]¶
Queries the archive for elites with the given batch of measures.
This method operates in batch. It takes in a batch of measures and outputs the batched data for the elites:
occupied, elites = archive.retrieve(...) occupied # Shape: (batch_size,) elites["solution"] # Shape: (batch_size, solution_dim) elites["objective"] # Shape: (batch_size, objective_dim) elites["measures"] # Shape: (batch_size, measure_dim) ...occupiedindicates whether an elite was found for each measure, i.e., whether the archive was occupied at each queried measure. Ifoccupied[i]is True, thenelites["solution"][i],elites["objective"][i],elites["measures"][i], and other fields will contain the data of the elite for the inputmeasures[i]. Ifoccupied[i]is False, then those fields will instead have arbitrary values, e.g.,elites["solution"][i]may be set to all NaN.- Parameters:¶
- measures: numpy.typing.ArrayLike¶
(batch_size,
measure_dim) array of measure space points at which to retrieve solutions.
- Returns:¶
2-element tuple of (boolean
occupiedarray, dict of elite data). See above for description.- Raises:¶
ValueError –
measuresis not of shape (batch_size,measure_dim).ValueError –
measureshas non-finite values (inf or NaN).
- retrieve_single(measures: numpy.typing.ArrayLike) tuple[bool, dict[str, Any]][source]¶
Queries the archive for an elite with the given measures.
While
retrieve()takes in a batch of measures, this method takes in the measures for only one solution and returns a single bool and a dict with single entries:occupied, elite = archive.retrieve_single(...) occupied # Bool elite["solution"] # Shape: (solution_dim,) elite["objective"] # Shape: (objective_dim,) elite["measures"] # Shape: (measure_dim,) ...- Parameters:¶
- measures: numpy.typing.ArrayLike¶
(
measure_dim,) array of measures.
- Returns:¶
2-element tuple of (boolean, dict of data for one elite)
- Raises:¶
ValueError –
measuresis not of shape (measure_dim,).ValueError –
measureshas non-finite values (inf or NaN).
-
sample_elites(n: int | integer, replace: bool =
True) dict[str, ndarray][source]¶ Randomly samples elites from the archive.
Currently, this sampling is done uniformly at random, either with or without replacement. Additional sampling methods may be supported in the future.
Example
elites = archive.sample_elites(16) elites["solution"] # Shape: (16, solution_dim) elites["objective"] elites["measures"] ...- Parameters:¶
- Returns:¶
A batch of elites randomly selected from the archive.
- Raises:¶
IndexError – The archive is empty.
ValueError –
nwas greater than the number of elites in the archive whenreplace=False.
- property best_elite : dict[str, Any]¶
The elite with the highest objective in the archive.
None if there are no elites in the archive.
Note
If the archive is non-elitist (this occurs when using the archive with a learning rate which is not 1.0, as in CMA-MAE), then this best elite may no longer exist in the archive because it was replaced with an elite with a lower objective value. This can happen because in non-elitist archives, new solutions only need to exceed the threshold of the cell they are being inserted into, not the objective of the elite currently in the cell. See #314 for more info.
Note
The best elite will contain a “threshold” key. This threshold is the threshold of the best elite’s cell after the best elite was inserted into the archive.
- property interval_size : ndarray¶
(
measure_dim,) array listing the size of each dim (upper_bounds - lower_bounds).
- property lower_bounds : ndarray¶
(
measure_dim,) array listing the lower bound of each dimension.
- property objective_dim : tuple[()] | int | integer¶
Dimensionality of the objective space.
The empty tuple
()indicates a scalar objective.
- property solution_dim : int | integer | tuple[int | integer, ...]¶
Dimensionality of the solution space.
- property stats : ArchiveStats¶
Statistics about the archive.
See
ArchiveStatsfor more info.
- property upper_bounds : ndarray¶
(
measure_dim,) array listing the upper bound of each dimension.