Incorporating Human Feedback into Quality Diversity for Diversified Text-to-Image Generation¶
![]()
by Li Ding, author of Quality Diversity through Human Feedback (QDHF); edited and reviewed by Bryon Tjanaka
This tutorial is part of the series of pyribs tutorials! See here for the list of all tutorials and the order in which they should be read.
Foundation models such as large language models (LLMs) and text-to-image generation models (Stable Diffusion, DALL·E, etc.) in effect compress vast archives of human knowledge into powerful and flexible tools, serving as a foundation for down-stream applications. One mechanism to build upon such foundational knowledge is reinforcement learning from human feedback (RLHF), which can make models both easier to use (by aligning them to human instructions), and more competent (by improving their capabilities based on human preferences).
RLHF is a relatively new paradigm, and its deployments often follow the relatively narrow recipe of maximizing a learned reward model of averaged human preferences over model responses. However, there are drawbacks when it is used to optimize for average human preferences, especially in generative tasks that demand diverse and creative model responses. On the other hand, Quality Diversity (QD) algorithms excel at identifying diverse and high-quality solutions but often rely on manually-crafted diversity metrics, as shown in previous examples, such as DQD.
In this work, we introduce Quality Diversity through Human Feedback (QDHF), which aims to broaden the RLHF recipe to include optimizing for interesting diversity among responses, which is of practical importance for many creative applications such as text-to-image generation. Such increased diversity can also improve optimization for complex and open-ended tasks (through improved exploration), personalization (serving individual rather than average human preference), and fairness (to offset algorithmic biases in gender, ethnicity, and more).
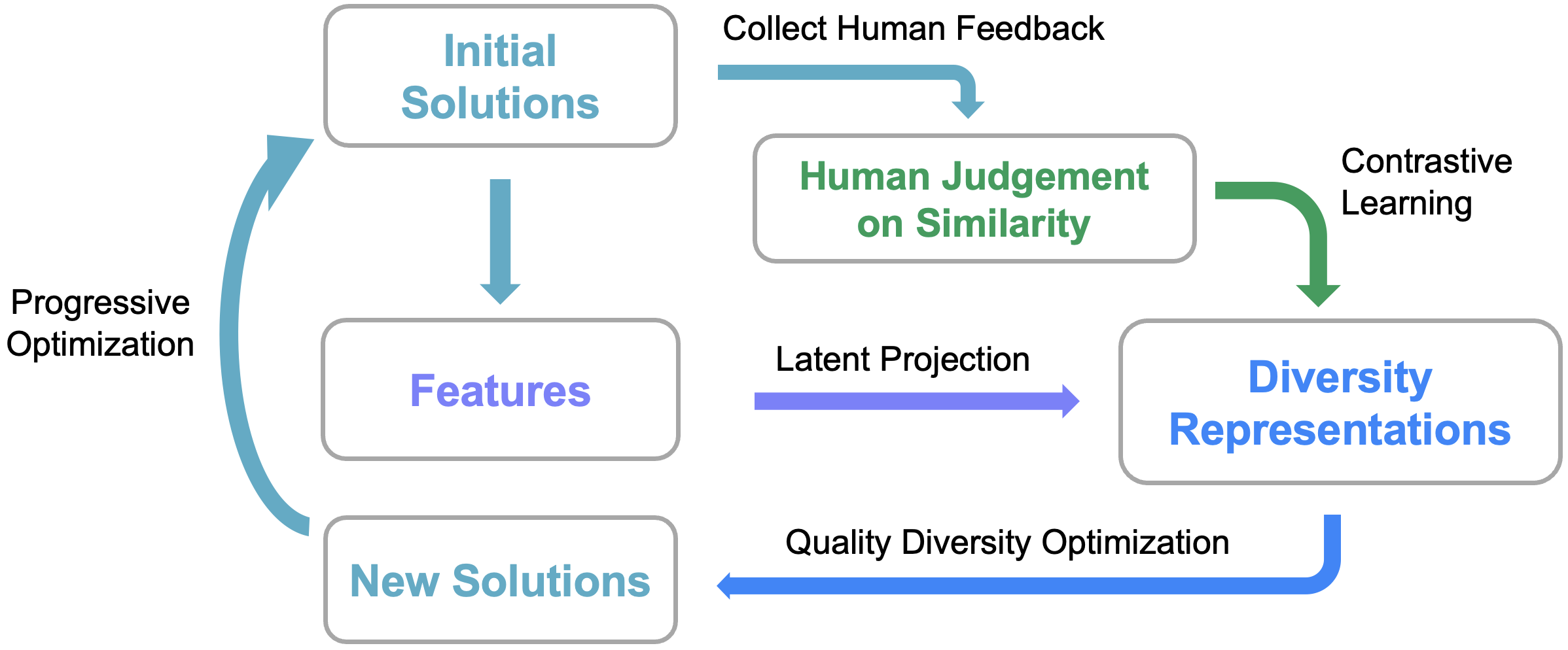
Our main idea is to derive distinct representations of what humans find interestingly different, and use such diversity representations to support optimization. An overview of our method is shown in the diagram above.
In this tutorial, we implement QDHF for the latent space illumination (LSI) experiment. LSI uses QD algorithms to search for a diverse collection of images in a GAN’s latent space, which has been introduced in the previous DQD tutorial. However, instead of generating images of a celebrity, this LSI pipeline uses Stable Diffusion to generate diverse images according to a given text prompt, like the one shown below (prompt: an image of a bear in a national park).

Another difference in this tutorial is that, QDHF uses human feedback to derive meaningful diversity metrics, not by manually specifying attributes such as age and hair length. We use a preference model, DreamSim, which is trained on a dataset of human judgment of similarity between images, to source feedback in QDHF optimization. Specifically, we implement QDHF with Map-Elites, and run it with the Stable Diffusion+CLIP pipeline.
This tutorial assumes that you are familiar with Latent Space Illumination (LSI). If you are not yet familiar with it, we recommend reviewing the DQD tutorial which generates Tom Cruise Images or the LSI MNIST tutorial which generates diverse MNIST digits.
Setup¶
Since Stable Diffusion, CLIP, and DreamSim are fairly large models, you will need a GPU to run this tutorial. On Colab, activate the GPU by clicking “Runtime” in the toolbar at the top. Then, click “Change Runtime Type”, and select “GPU”.
Below, we check what GPU has been provided. The possible GPUs (at the time of writing) are as follows; factory reset the runtime if you do not have a desired GPU.
V100 = Excellent (Available only for Colab Pro users)
P100 = Very Good
T4 = Good (preferred)
K80 = Meh
P4 = (Not Recommended)
!nvidia-smi -L
GPU 0: NVIDIA RTX A6000 (UUID: GPU-76b34a40-ef0b-e82b-762b-652c7fb7e93c)
Now, we install various libraries, including pyribs, CLIP, Stable Diffusion, and DreamSim. This cell will take around 5-10 minutes to run since it involves downloading multiple large files.
%pip install ribs[visualize] torch torchvision git+https://github.com/openai/CLIP tqdm dreamsim diffusers accelerate
import sys
import time
import numpy as np
from tqdm import tqdm, trange
Let’s first set up CUDA for PyTorch. We use float16 to save GPU memories for large models.
import torch
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.cuda.empty_cache()
print("Torch device:", DEVICE)
# Use float16 for GPU, float32 for CPU.
TORCH_DTYPE = torch.float16 if torch.cuda.is_available() else torch.float32
print("Torch dtype:", TORCH_DTYPE)
Torch device: cuda
Torch dtype: torch.float16
Preliminaries: CLIP, Stable Diffusion, and DreamSim¶
Below we set up CLIP, Stable Diffusion, and DreamSim. The code for these models is adopted from the DQD tutorial, the DreamSim demo, and the Hugging Face Stable Diffusion example. Each cell may take around 3 minutes to run since it involves downloading multiple large files.
Since this section is focused on the LSI pipeline rather than on pyribs, feel free to skim past and come back to it later.
CLIP for Connecting Text and Images¶
import clip
# This tutorial uses ViT-B/32, you may use other checkpoints depending on your resources and need.
CLIP_MODEL, CLIP_PREPROCESS = clip.load("ViT-B/32", device=DEVICE)
CLIP_MODEL.eval()
for p in CLIP_MODEL.parameters():
p.requires_grad_(False)
def compute_clip_scores(imgs, text, return_clip_features=False):
"""Computes CLIP scores for a batch of images and a given text prompt."""
img_tensor = torch.stack([CLIP_PREPROCESS(img) for img in imgs]).to(DEVICE)
tokenized_text = clip.tokenize([text]).to(DEVICE)
img_logits, _text_logits = CLIP_MODEL(img_tensor, tokenized_text)
img_logits = img_logits.detach().cpu().numpy().astype(np.float32)[:, 0]
img_logits = 1 / img_logits * 100
# Remap the objective from minimizing [0, 10] to maximizing [0, 100]
img_logits = (10.0 - img_logits) * 10.0
if return_clip_features:
clip_features = CLIP_MODEL.encode_image(img_tensor).to(TORCH_DTYPE)
return img_logits, clip_features
else:
return img_logits
DreamSim for Simulating Human Feedback¶
from dreamsim import dreamsim
DREAMSIM_MODEL, DREAMSIM_PREPROCESS = dreamsim(
pretrained=True, dreamsim_type="open_clip_vitb32", device=DEVICE
)
/home/tjanaka/pyribs/env/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Downloading checkpoint
100%|████████████████████████████████| 313M/313M [00:04<00:00, 65.9MB/s]
Unzipping...
/home/tjanaka/pyribs/env/lib/python3.12/site-packages/peft/tuners/tuners_utils.py:196: UserWarning: Already found a `peft_config` attribute in the model. This will lead to having multiple adapters in the model. Make sure to know what you are doing!
warnings.warn(
Stable Diffusion for Generating Images¶
By default, we use the miniSD-diffusers checkpoint, which generates images at 256x256 for faster inference and less GPU memory usage. Please switch to the stable-diffusion-2-1-base checkpoint to generate images with higher resolution and quality.
from diffusers import StableDiffusionPipeline
IMG_WIDTH = 256
IMG_HEIGHT = 256
SD_IN_HEIGHT = 32
SD_IN_WIDTH = 32
SD_CHECKPOINT = "lambdalabs/miniSD-diffusers"
# IMG_WIDTH = 512
# IMG_HEIGHT = 512
# SD_IN_HEIGHT = 64
# SD_IN_WIDTH = 64
# SD_CHECKPOINT = "stabilityai/stable-diffusion-2-1-base"
BATCH_SIZE = 4
SD_IN_CHANNELS = 4
SD_IN_SHAPE = (
BATCH_SIZE,
SD_IN_CHANNELS,
SD_IN_HEIGHT,
SD_IN_WIDTH,
)
SDPIPE = StableDiffusionPipeline.from_pretrained(
SD_CHECKPOINT,
torch_dtype=TORCH_DTYPE,
safety_checker=None, # For faster inference.
requires_safety_checker=False,
)
SDPIPE.set_progress_bar_config(disable=True)
SDPIPE = SDPIPE.to(DEVICE)
Fetching 13 files: 100%|████████████████| 13/13 [00:36<00:00, 2.79s/it]
Loading pipeline components...: 0%| | 0/6 [00:00<?, ?it/s]`torch_dtype` is deprecated! Use `dtype` instead!
Loading pipeline components...: 17%|▊ | 1/6 [00:00<00:01, 2.85it/s]An error occurred while trying to fetch /home/tjanaka/.cache/huggingface/hub/models--lambdalabs--miniSD-diffusers/snapshots/26ed8a9bfbf76f46a6cf60517dde321f900c44ce/unet: Error no file named diffusion_pytorch_model.safetensors found in directory /home/tjanaka/.cache/huggingface/hub/models--lambdalabs--miniSD-diffusers/snapshots/26ed8a9bfbf76f46a6cf60517dde321f900c44ce/unet.
Defaulting to unsafe serialization. Pass `allow_pickle=False` to raise an error instead.
Loading pipeline components...: 33%|█▋ | 2/6 [00:00<00:01, 2.00it/s]An error occurred while trying to fetch /home/tjanaka/.cache/huggingface/hub/models--lambdalabs--miniSD-diffusers/snapshots/26ed8a9bfbf76f46a6cf60517dde321f900c44ce/vae: Error no file named diffusion_pytorch_model.safetensors found in directory /home/tjanaka/.cache/huggingface/hub/models--lambdalabs--miniSD-diffusers/snapshots/26ed8a9bfbf76f46a6cf60517dde321f900c44ce/vae.
Defaulting to unsafe serialization. Pass `allow_pickle=False` to raise an error instead.
Loading pipeline components...: 100%|█████| 6/6 [00:01<00:00, 5.44it/s]
Aligning Diversity Metrics with Human Preferences¶
Next, we define a latent projection model to characterize diversity from image features through constrastive learning from human feedback.
The DivProj model projects the image features (e.g., CLIP features with 512-d) onto a low-dimensional latent space (e.g., 2-d), where each dimension represents a numeric diversity metric.
An intuitive example is that the model may learn “object size” as a metric, where low values mean the object is small and high values mean it is large.
from torch import nn
class DivProj(nn.Module):
def __init__(self, input_dim, latent_dim=2):
super().__init__()
self.proj = nn.Sequential(
nn.Linear(in_features=input_dim, out_features=latent_dim),
)
def forward(self, x):
"""Get diversity representations."""
x = self.proj(x)
return x
def calc_dis(self, x1, x2):
"""Calculate diversity distance as (squared) L2 distance."""
x1 = self.forward(x1)
x2 = self.forward(x2)
return torch.sum(torch.square(x1 - x2), -1)
def triplet_delta_dis(self, ref, x1, x2):
"""Calculate delta distance comparing x1 and x2 to ref."""
x1 = self.forward(x1)
x2 = self.forward(x2)
ref = self.forward(ref)
return torch.sum(torch.square(ref - x1), -1) - torch.sum(
torch.square(ref - x2), -1
)
Constrastive Learning for Diversity Projection¶
For contrastive learning, we use a triplet loss to train the diversity projection model. This loss encourages the model to project similar images close to each other in the latent space, and dissimilar images far from each other. The preference labels are given by the DreamSim model, which is pre-trained on the human feedback on image similarity, so we will use it as the source of feedback here.
To avoid redundancy in computation, we first extract DreamSim features from the images, and then calculate the cosine similarity of DreamSim features. This is equivalent to using the DreamSim model directly to calculate the similarity.
The whole fit_div_proj process works as follows: The input data is with shape of (n, 3, image_size, image_size), where n is the number of triplets. The second dimension of 3 represents the reference, positive, and negative images. We split the data into traning and validation sets, and then train the diversity projection model with the triplet loss. The output is a diversity projection model that projects image features onto a low-dimensional latent space, where each dimension represents a numeric diversity metric.
# Triplet loss with margin 0.05.
# The binary preference labels are scaled to y = 1 or -1 for the loss, where y = 1 means x2 is more similar to ref than x1.
loss_fn = lambda y, delta_dis: torch.max( # noqa: E731
torch.tensor([0.0]).to(DEVICE), 0.05 - (y * 2 - 1) * delta_dis
).mean()
def fit_div_proj(inputs, dreamsim_features, latent_dim, batch_size=32):
"""Trains the DivProj model on ground-truth labels."""
t = time.time()
model = DivProj(input_dim=inputs.shape[-1], latent_dim=latent_dim)
model.to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
n_pref_data = inputs.shape[0]
ref = inputs[:, 0]
x1 = inputs[:, 1]
x2 = inputs[:, 2]
n_train = int(n_pref_data * 0.75)
n_val = n_pref_data - n_train
# Split data into train and val.
ref_train = ref[:n_train]
x1_train = x1[:n_train]
x2_train = x2[:n_train]
ref_val = ref[n_train:]
x1_val = x1[n_train:]
x2_val = x2[n_train:]
# Split DreamSim features into train and val.
ref_dreamsim_features = dreamsim_features[:, 0]
x1_dreamsim_features = dreamsim_features[:, 1]
x2_dreamsim_features = dreamsim_features[:, 2]
ref_gt_train = ref_dreamsim_features[:n_train]
x1_gt_train = x1_dreamsim_features[:n_train]
x2_gt_train = x2_dreamsim_features[:n_train]
ref_gt_val = ref_dreamsim_features[n_train:]
x1_gt_val = x1_dreamsim_features[n_train:]
x2_gt_val = x2_dreamsim_features[n_train:]
val_acc = []
n_iters_per_epoch = max((n_train) // batch_size, 1)
for epoch in range(200):
for _ in range(n_iters_per_epoch):
optimizer.zero_grad()
idx = np.random.choice(n_train, batch_size)
batch_ref = ref_train[idx].float()
batch1 = x1_train[idx].float()
batch2 = x2_train[idx].float()
# Get delta distance from model.
delta_dis = model.triplet_delta_dis(batch_ref, batch1, batch2)
# Get preference labels from DreamSim features.
gt_dis = torch.nn.functional.cosine_similarity(
ref_gt_train[idx], x2_gt_train[idx], dim=-1
) - torch.nn.functional.cosine_similarity(
ref_gt_train[idx], x1_gt_train[idx], dim=-1
)
gt = (gt_dis > 0).to(TORCH_DTYPE)
loss = loss_fn(gt, delta_dis)
loss.backward()
optimizer.step()
# Validate.
n_correct = 0
n_total = 0
with torch.no_grad():
idx = np.arange(n_val)
batch_ref = ref_val[idx].float()
batch1 = x1_val[idx].float()
batch2 = x2_val[idx].float()
delta_dis = model.triplet_delta_dis(batch_ref, batch1, batch2)
pred = delta_dis > 0
gt_dis = torch.nn.functional.cosine_similarity(
ref_gt_val[idx], x2_gt_val[idx], dim=-1
) - torch.nn.functional.cosine_similarity(
ref_gt_val[idx], x1_gt_val[idx], dim=-1
)
gt = gt_dis > 0
n_correct += (pred == gt).sum().item()
n_total += len(idx)
acc = n_correct / n_total
val_acc.append(acc)
# Early stopping if val_acc does not improve for 10 epochs.
if epoch > 10 and np.mean(val_acc[-10:]) < np.mean(val_acc[-11:-1]):
break
print(
f"{np.round(time.time() - t, 1)}s ({epoch + 1} epochs) | DivProj (n={n_pref_data}) fitted with val acc.: {acc}"
)
return model.to(TORCH_DTYPE), acc
Helper Functions to Compute Objectives and Measures¶
def compute_diversity_measures(clip_features, diversity_model):
with torch.no_grad():
measures = diversity_model(clip_features).detach().cpu().numpy()
return measures
def evaluate_lsi(
latents,
prompt,
return_features=False,
diversity_model=None,
):
"""Evaluates the objective of LSI for a batch of latents and a given text prompt."""
images = SDPIPE(
prompt,
num_images_per_prompt=latents.shape[0],
latents=latents,
# num_inference_steps=1, # For testing.
).images
objs, clip_features = compute_clip_scores(
images,
prompt,
return_clip_features=True,
)
images = torch.cat([DREAMSIM_PREPROCESS(img) for img in images]).to(DEVICE)
dreamsim_features = DREAMSIM_MODEL.embed(images)
if diversity_model is not None:
measures = compute_diversity_measures(clip_features, diversity_model)
else:
measures = None
if return_features:
return objs, measures, clip_features, dreamsim_features
else:
return objs, measures
QDHF with pyribs¶
To use QDHF to generate diverse collections of images, we will use the MAP-Elites algorithm, where the diversity metrics are progressively trained and fine-tuned during optimization.
Algorithm Setup¶
To set up the MAP-Elites instance for QDHF, we will set up the following components. First, we create the GridArchive. The archive is 20x20 and stores Stable Diffusion latent vectors. The dimensions of vectors are (BATCH, 4, H, W) where H=W=32 if generating 256x256 images with miniSD, or 64 for 512x512 images with stable-diffusion-2-1-base. Next, we create a GaussianEmitter that generates solutions by mutating existing archive solutions with Gaussian noise. Finally, we set up a Scheduler to combine everything together.
# ruff: noqa: NPY002
from ribs.archives import GridArchive
from ribs.emitters import GaussianEmitter
from ribs.schedulers import Scheduler
GRID_SIZE = (20, 20)
SEED = 123
np.random.seed(SEED)
torch.manual_seed(SEED)
def tensor_to_list(tensor):
sols = tensor.detach().cpu().numpy().astype(np.float32)
return sols.reshape(sols.shape[0], -1)
def list_to_tensor(list_):
sols = np.array(list_).reshape(
len(list_), 4, SD_IN_HEIGHT, SD_IN_WIDTH
) # Hard-coded for now.
return torch.tensor(sols, dtype=TORCH_DTYPE, device=DEVICE)
def create_scheduler(
sols,
objs,
clip_features,
diversity_model,
seed=None,
):
measures = compute_diversity_measures(clip_features, diversity_model)
archive_bounds = np.array(
[np.quantile(measures, 0.01, axis=0), np.quantile(measures, 0.99, axis=0)]
).T
sols = tensor_to_list(sols)
# Set up archive.
archive = GridArchive(
solution_dim=len(sols[0]), dims=GRID_SIZE, ranges=archive_bounds, seed=seed
)
# Add initial solutions to the archive.
archive.add(sols, objs, measures)
# Set up the GaussianEmitter.
emitters = [
GaussianEmitter(
archive=archive,
sigma=0.1,
initial_solutions=archive.sample_elites(BATCH_SIZE)["solution"],
batch_size=BATCH_SIZE,
seed=seed,
)
]
# Return the archive and scheduler.
return archive, Scheduler(archive, emitters)
LSI with QDHF¶
Having set up the necessary components above, we now run QDHF to search for images of a given prompt. The default prompt is “an astronaut riding a horse on mars”.
Training¶
The execution loop is similar to the experiments in previous tutorials. The main difference is that when the iteration is in update_schedule, we will update the QD archive by fine-tuning the diversity metrics and adding current solutions to the archive again with regard to their updated diversity measures.
The total number of iterations is set to be 200, and it should take ~45min to run on a GPU.
# Change here for whatever you would like to generate.
prompt = "an astronaut riding a horse on mars"
INIT_POP = 200 # Initial population.
TOTAL_ITRS = 200 # Total number of iterations.
update_schedule = [1, 21, 51, 101] # Iterations on which to update the archive.
n_pref_data = 1000 # Number of preferences used in each update.
archive: GridArchive = None
best = 0.0
for itr in trange(1, TOTAL_ITRS + 1, file=sys.stdout, desc="Iterations"):
itr_start = time.time()
# Update archive and scheduler if needed.
if itr in update_schedule:
if archive is None:
tqdm.write("Initializing archive and diversity projection.")
all_sols = []
all_clip_features = []
all_dreamsim_features = []
all_objs = []
# Sample random solutions and get judgment on similarity.
n_batches = INIT_POP // BATCH_SIZE
for _ in range(n_batches):
sols = torch.randn(SD_IN_SHAPE, device=DEVICE, dtype=TORCH_DTYPE)
objs, _, clip_features, dreamsim_features = evaluate_lsi(
sols, prompt, return_features=True
)
all_sols.append(sols)
all_clip_features.append(clip_features)
all_dreamsim_features.append(dreamsim_features)
all_objs.append(objs)
all_sols = torch.concat(all_sols, dim=0)
all_clip_features = torch.concat(all_clip_features, dim=0)
all_dreamsim_features = torch.concat(all_dreamsim_features, dim=0)
all_objs = np.concatenate(all_objs, axis=0)
# Initialize the diversity projection model.
div_proj_data = []
div_proj_labels = []
for _ in range(n_pref_data):
idx = np.random.choice(all_sols.shape[0], 3)
div_proj_data.append(all_clip_features[idx])
div_proj_labels.append(all_dreamsim_features[idx])
div_proj_data = torch.concat(div_proj_data, dim=0)
div_proj_labels = torch.concat(div_proj_labels, dim=0)
div_proj_data = div_proj_data.reshape(n_pref_data, 3, -1)
div_proj_label = div_proj_labels.reshape(n_pref_data, 3, -1)
diversity_model, div_proj_acc = fit_div_proj(
div_proj_data,
div_proj_label,
latent_dim=2,
)
else:
tqdm.write("Updating archive and diversity projection.")
# Get all the current solutions and collect feedback.
all_sols = list_to_tensor(archive.data("solution"))
n_batches = np.ceil(len(all_sols) / BATCH_SIZE).astype(int)
all_clip_features = []
all_dreamsim_features = []
all_objs = []
for i in range(n_batches):
sols = all_sols[i * BATCH_SIZE : (i + 1) * BATCH_SIZE]
objs, _, clip_features, dreamsim_features = evaluate_lsi(
sols, prompt, return_features=True
)
all_clip_features.append(clip_features)
all_dreamsim_features.append(dreamsim_features)
all_objs.append(objs)
all_clip_features = torch.concat(
all_clip_features, dim=0
) # n_pref_data * 3, dim
all_dreamsim_features = torch.concat(all_dreamsim_features, dim=0)
all_objs = np.concatenate(all_objs, axis=0)
# Update the diversity projection model.
additional_features = []
additional_labels = []
for _ in range(n_pref_data):
idx = np.random.choice(all_sols.shape[0], 3)
additional_features.append(all_clip_features[idx])
additional_labels.append(all_dreamsim_features[idx])
additional_features = torch.concat(additional_features, dim=0)
additional_labels = torch.concat(additional_labels, dim=0)
additional_div_proj_data = additional_features.reshape(n_pref_data, 3, -1)
additional_div_proj_label = additional_labels.reshape(n_pref_data, 3, -1)
div_proj_data = torch.concat(
(div_proj_data, additional_div_proj_data), dim=0
)
div_proj_label = torch.concat(
(div_proj_label, additional_div_proj_label), dim=0
)
diversity_model, div_proj_acc = fit_div_proj(
div_proj_data,
div_proj_label,
latent_dim=2,
)
archive, scheduler = create_scheduler(
all_sols,
all_objs,
all_clip_features,
diversity_model,
seed=SEED,
)
# Primary QD loop.
sols = scheduler.ask()
sols = list_to_tensor(sols)
objs, measures, clip_features, dreamsim_features = evaluate_lsi(
sols, prompt, return_features=True, diversity_model=diversity_model
)
best = max(best, *objs)
scheduler.tell(objs, measures)
# This can be used as a flag to save on the final iteration, but note that
# we do not save results in this tutorial.
final_itr = itr == TOTAL_ITRS
# Update the summary statistics for the archive.
qd_score, coverage = archive.stats.norm_qd_score, archive.stats.coverage
tqdm.write(f"QD score: {np.round(qd_score, 2)} Coverage: {coverage * 100}")
Initializing archive and diversity projection.
Iterations: 0%| | 0/200 [00:00<?, ?it/s]0.7s (14 epochs) | DivProj (n=1000) fitted with val acc.: 0.74
QD score: 24.97 Coverage: 34.5
QD score: 25.52 Coverage: 35.25
QD score: 26.06 Coverage: 36.0
QD score: 26.24 Coverage: 36.25
QD score: 26.6 Coverage: 36.75
QD score: 26.97 Coverage: 37.25
QD score: 27.33 Coverage: 37.75
QD score: 27.86 Coverage: 38.5
QD score: 28.03 Coverage: 38.75
QD score: 28.2 Coverage: 39.0
QD score: 28.57 Coverage: 39.5
QD score: 28.58 Coverage: 39.5
QD score: 28.94 Coverage: 40.0
QD score: 29.12 Coverage: 40.25
QD score: 29.67 Coverage: 41.0
QD score: 29.85 Coverage: 41.25
QD score: 30.04 Coverage: 41.5
QD score: 30.21 Coverage: 41.75
QD score: 30.39 Coverage: 42.0
QD score: 30.39 Coverage: 42.0
Updating archive and diversity projection.
Iterations: 10%|██▏ | 20/200 [02:33<06:45, 2.25s/it]1.0s (15 epochs) | DivProj (n=2000) fitted with val acc.: 0.774
QD score: 21.38 Coverage: 29.5
QD score: 21.57 Coverage: 29.75
QD score: 22.11 Coverage: 30.5
QD score: 22.49 Coverage: 31.0
QD score: 22.67 Coverage: 31.25
QD score: 23.23 Coverage: 32.0
QD score: 23.76 Coverage: 32.75
QD score: 24.13 Coverage: 33.25
QD score: 24.3 Coverage: 33.5
QD score: 25.03 Coverage: 34.5
QD score: 25.03 Coverage: 34.5
QD score: 25.75 Coverage: 35.5
QD score: 25.92 Coverage: 35.75
QD score: 26.29 Coverage: 36.25
QD score: 26.66 Coverage: 36.75
QD score: 27.39 Coverage: 37.75
QD score: 27.57 Coverage: 38.0
QD score: 27.94 Coverage: 38.5
QD score: 28.48 Coverage: 39.25
QD score: 28.65 Coverage: 39.5
QD score: 29.02 Coverage: 40.0
QD score: 29.57 Coverage: 40.75
QD score: 29.92 Coverage: 41.25
QD score: 30.09 Coverage: 41.5
QD score: 30.44 Coverage: 42.0
QD score: 30.63 Coverage: 42.25
QD score: 30.81 Coverage: 42.5
QD score: 30.81 Coverage: 42.5
QD score: 31.01 Coverage: 42.75
QD score: 31.01 Coverage: 42.75
Updating archive and diversity projection.
Iterations: 25%|█████▌ | 50/200 [05:13<04:47, 1.92s/it]2.2s (15 epochs) | DivProj (n=3000) fitted with val acc.: 0.8066666666666666
QD score: 21.81 Coverage: 30.0
QD score: 21.81 Coverage: 30.0
QD score: 22.0 Coverage: 30.25
QD score: 22.37 Coverage: 30.75
QD score: 22.72 Coverage: 31.25
QD score: 23.25 Coverage: 32.0
QD score: 23.43 Coverage: 32.25
QD score: 23.8 Coverage: 32.75
QD score: 23.98 Coverage: 33.0
QD score: 23.98 Coverage: 33.0
QD score: 24.34 Coverage: 33.5
QD score: 24.51 Coverage: 33.75
QD score: 24.69 Coverage: 34.0
QD score: 24.87 Coverage: 34.25
QD score: 25.41 Coverage: 35.0
QD score: 26.13 Coverage: 36.0
QD score: 26.31 Coverage: 36.25
QD score: 26.86 Coverage: 37.0
QD score: 27.05 Coverage: 37.25
QD score: 27.22 Coverage: 37.5
QD score: 27.4 Coverage: 37.75
QD score: 27.58 Coverage: 38.0
QD score: 27.94 Coverage: 38.5
QD score: 27.94 Coverage: 38.5
QD score: 28.13 Coverage: 38.75
QD score: 28.31 Coverage: 39.0
QD score: 28.5 Coverage: 39.25
QD score: 28.86 Coverage: 39.75
QD score: 29.42 Coverage: 40.5
QD score: 29.6 Coverage: 40.75
QD score: 29.78 Coverage: 41.0
QD score: 30.33 Coverage: 41.75
QD score: 30.33 Coverage: 41.75
QD score: 30.51 Coverage: 42.0
QD score: 30.69 Coverage: 42.25
QD score: 30.87 Coverage: 42.5
QD score: 30.87 Coverage: 42.5
QD score: 30.87 Coverage: 42.5
QD score: 31.25 Coverage: 43.0
QD score: 31.43 Coverage: 43.25
QD score: 31.62 Coverage: 43.5
QD score: 31.62 Coverage: 43.5
QD score: 31.98 Coverage: 44.0
QD score: 32.35 Coverage: 44.5
QD score: 32.35 Coverage: 44.5
QD score: 32.35 Coverage: 44.5
QD score: 32.35 Coverage: 44.5
QD score: 32.71 Coverage: 45.0
QD score: 32.88 Coverage: 45.25
QD score: 33.07 Coverage: 45.5
Updating archive and diversity projection.
Iterations: 50%|██████████▌ | 100/200 [08:42<03:11, 1.92s/it]1.6s (12 epochs) | DivProj (n=4000) fitted with val acc.: 0.8
QD score: 23.27 Coverage: 32.0
QD score: 23.44 Coverage: 32.25
QD score: 23.63 Coverage: 32.5
QD score: 23.81 Coverage: 32.75
QD score: 24.16 Coverage: 33.25
QD score: 24.34 Coverage: 33.5
QD score: 24.53 Coverage: 33.75
QD score: 24.71 Coverage: 34.0
QD score: 24.9 Coverage: 34.25
QD score: 25.09 Coverage: 34.5
QD score: 25.43 Coverage: 35.0
QD score: 25.79 Coverage: 35.5
QD score: 26.16 Coverage: 36.0
QD score: 26.53 Coverage: 36.5
QD score: 26.92 Coverage: 37.0
QD score: 27.27 Coverage: 37.5
QD score: 27.83 Coverage: 38.25
QD score: 28.01 Coverage: 38.5
QD score: 28.38 Coverage: 39.0
QD score: 28.57 Coverage: 39.25
QD score: 28.93 Coverage: 39.75
QD score: 29.3 Coverage: 40.25
QD score: 29.66 Coverage: 40.75
QD score: 30.03 Coverage: 41.25
QD score: 30.39 Coverage: 41.75
QD score: 30.4 Coverage: 41.75
QD score: 30.4 Coverage: 41.75
QD score: 30.57 Coverage: 42.0
QD score: 30.92 Coverage: 42.5
QD score: 31.28 Coverage: 43.0
QD score: 31.65 Coverage: 43.5
QD score: 32.19 Coverage: 44.25
QD score: 32.37 Coverage: 44.5
QD score: 32.56 Coverage: 44.75
QD score: 32.74 Coverage: 45.0
QD score: 32.92 Coverage: 45.25
QD score: 33.1 Coverage: 45.5
QD score: 33.11 Coverage: 45.5
QD score: 33.29 Coverage: 45.75
QD score: 33.64 Coverage: 46.25
QD score: 33.82 Coverage: 46.5
QD score: 33.83 Coverage: 46.5
QD score: 33.83 Coverage: 46.5
QD score: 33.83 Coverage: 46.5
QD score: 34.01 Coverage: 46.75
QD score: 34.2 Coverage: 47.0
QD score: 34.56 Coverage: 47.5
QD score: 34.56 Coverage: 47.5
QD score: 34.75 Coverage: 47.75
QD score: 34.75 Coverage: 47.75
QD score: 35.11 Coverage: 48.25
QD score: 35.28 Coverage: 48.5
QD score: 35.46 Coverage: 48.75
QD score: 35.65 Coverage: 49.0
QD score: 35.84 Coverage: 49.25
QD score: 36.02 Coverage: 49.5
QD score: 36.22 Coverage: 49.75
QD score: 36.4 Coverage: 50.0
QD score: 36.42 Coverage: 50.0
QD score: 36.79 Coverage: 50.5
QD score: 36.97 Coverage: 50.74999999999999
QD score: 36.97 Coverage: 50.74999999999999
QD score: 37.15 Coverage: 51.0
QD score: 37.15 Coverage: 51.0
QD score: 37.33 Coverage: 51.24999999999999
QD score: 37.69 Coverage: 51.74999999999999
QD score: 37.69 Coverage: 51.74999999999999
QD score: 37.69 Coverage: 51.74999999999999
QD score: 37.88 Coverage: 52.0
QD score: 37.89 Coverage: 52.0
QD score: 38.07 Coverage: 52.25
QD score: 38.07 Coverage: 52.25
QD score: 38.44 Coverage: 52.75
QD score: 38.45 Coverage: 52.75
QD score: 38.63 Coverage: 53.0
QD score: 38.65 Coverage: 53.0
QD score: 38.67 Coverage: 53.0
QD score: 38.85 Coverage: 53.25
QD score: 39.04 Coverage: 53.5
QD score: 39.04 Coverage: 53.5
QD score: 39.21 Coverage: 53.75
QD score: 39.4 Coverage: 54.0
QD score: 39.4 Coverage: 54.0
QD score: 39.76 Coverage: 54.50000000000001
QD score: 40.11 Coverage: 55.00000000000001
QD score: 40.11 Coverage: 55.00000000000001
QD score: 40.11 Coverage: 55.00000000000001
QD score: 40.3 Coverage: 55.25
QD score: 40.3 Coverage: 55.25
QD score: 40.3 Coverage: 55.25
QD score: 40.48 Coverage: 55.50000000000001
QD score: 40.82 Coverage: 56.00000000000001
QD score: 41.0 Coverage: 56.25
QD score: 41.17 Coverage: 56.49999999999999
QD score: 41.35 Coverage: 56.75
QD score: 41.36 Coverage: 56.75
QD score: 41.73 Coverage: 57.25
QD score: 41.73 Coverage: 57.25
QD score: 41.74 Coverage: 57.25
QD score: 41.93 Coverage: 57.49999999999999
Iterations: 100%|█████████████████████| 200/200 [14:21<00:00, 4.31s/it]
Visualization¶
Visualizing the Archive¶
We use the grid_archive_heatmap function to visualize the grid archive as a heatmap.
from matplotlib import pyplot as plt
from ribs.visualize import grid_archive_heatmap
plt.figure(figsize=(6, 4.5))
grid_archive_heatmap(archive, aspect="equal", vmin=0, vmax=100)
plt.xlabel("Diversity Metric 1")
plt.ylabel("Diversity Metric 2")
Text(0, 0.5, 'Diversity Metric 2')

We can see that the archive is filled with diverse images, and the diversity metrics are well distributed.
Visualizing the Results¶
Now let’s view the images from across the archive generated by QDHF. We randomly sample images in the grid with measures spread across the diversity dimensions.
import itertools
# Modify this to determine how many images to plot along each dimension.
img_freq = (
4, # Number of columns of images.
4, # Number of rows of images.
)
# List of images.
imgs = []
# Convert archive to a df with solutions available.
df = archive.data(return_type="pandas")
# Compute the min and max measures for which solutions were found.
measure_bounds = np.array(
[
(df["measures_0"].min(), df["measures_0"].max()),
(df["measures_1"].min(), df["measures_1"].max()),
]
)
archive_bounds = np.array(
[archive.boundaries[0][[0, -1]], archive.boundaries[1][[0, -1]]]
)
delta_measures_0 = (archive_bounds[0][1] - archive_bounds[0][0]) / img_freq[0]
delta_measures_1 = (archive_bounds[1][1] - archive_bounds[1][0]) / img_freq[1]
for col, row in itertools.product(range(img_freq[1]), range(img_freq[0])):
# Compute bounds of a box in measure space.
measures_0_low = archive_bounds[0][0] + delta_measures_0 * row
measures_0_high = archive_bounds[0][0] + delta_measures_0 * (row + 1)
measures_1_low = archive_bounds[1][0] + delta_measures_1 * col
measures_1_high = archive_bounds[1][0] + delta_measures_1 * (col + 1)
if row == 0:
measures_0_low = measure_bounds[0][0]
if col == 0:
measures_1_low = measure_bounds[1][0]
if row == img_freq[0] - 1:
measures_0_high = measure_bounds[0][1]
if col == img_freq[1] - 1:
measures_0_high = measure_bounds[1][1]
# Query for a solution with measures within this box.
query_string = (
f"{measures_0_low} <= measures_0 & measures_0 <= {measures_0_high} & "
f"{measures_1_low} <= measures_1 & measures_1 <= {measures_1_high}"
)
df_box = df.query(query_string)
if not df_box.empty:
# Randomly sample a solution from the box.
# Stable Diffusion solutions have SD_IN_CHANNELS * SD_IN_HEIGHT * SD_IN_WIDTH
# dimensions, so the final solution col is solution_(x-1).
sol = (
df_box.loc[
:,
"solution_0" : f"solution_{SD_IN_CHANNELS * SD_IN_HEIGHT * SD_IN_WIDTH - 1}",
]
.sample(n=1)
.iloc[0]
)
# Convert the latent vector solution to an image.
latents = torch.tensor(sol.to_numpy()).reshape(
(1, SD_IN_CHANNELS, SD_IN_HEIGHT, SD_IN_WIDTH)
)
latents = latents.to(TORCH_DTYPE).to(DEVICE)
img = SDPIPE(
prompt,
num_images_per_prompt=1,
latents=latents,
# num_inference_steps=1, # For testing.
).images[0]
img = torch.from_numpy(np.array(img)).permute(2, 0, 1) / 255.0
imgs.append(img)
else:
imgs.append(torch.zeros((3, IMG_HEIGHT, IMG_WIDTH)))
And the images are plotted below as a single collage.
from torchvision.utils import make_grid
def create_archive_tick_labels(measure_range, num_ticks):
delta = (measure_range[1] - measure_range[0]) / num_ticks
ticklabels = [round(delta * p + measure_range[0], 3) for p in range(num_ticks + 1)]
return ticklabels
plt.figure(figsize=(img_freq[0] * 2, img_freq[0] * 2))
img_grid = make_grid(imgs, nrow=img_freq[0], padding=0)
img_grid = np.transpose(img_grid.cpu().numpy(), (1, 2, 0))
plt.imshow(img_grid)
plt.xlabel("")
num_x_ticks = img_freq[0]
x_ticklabels = create_archive_tick_labels(measure_bounds[0], num_x_ticks)
x_tick_range = img_grid.shape[1]
x_ticks = np.arange(0, x_tick_range + 1e-9, step=x_tick_range / num_x_ticks)
plt.xticks(x_ticks, x_ticklabels)
plt.ylabel("")
num_y_ticks = img_freq[1]
y_ticklabels = create_archive_tick_labels(measure_bounds[1], num_y_ticks)
y_ticklabels.reverse()
y_tick_range = img_grid.shape[0]
y_ticks = np.arange(0, y_tick_range + 1e-9, step=y_tick_range / num_y_ticks)
plt.yticks(y_ticks, y_ticklabels)
plt.tight_layout()

We can see that QDHF generates a diverse collection of images with some visible trends of diversity such as object size (smaller on upper left, larger on bottom right), scene layout (dark sky on the top, dusty sky on the bottom), etc.
This tutorial uses light-weight models and smaller batch sizes for faster inference. You should get better results using the official implementation of QDHF.
Conclusion¶
In this tutorial, we explored using the QDHF algorithm to generate diverse images given the text prompt. We showed how QDHF can be implemented using pyribs, and how we use it in a pipeline with Stable Diffusion. The generated images show variations and visible trends of diversity without the need to manually specify diversity metrics.
Citation¶
If you find this tutorial useful, please cite our paper:
@inproceedings{ding2024qdhf,
author = {Ding, Li and Zhang, Jenny and Clune, Jeff and Spector, Lee and Lehman, Joel},
title = {Quality diversity through human feedback: towards open-ended diversity-driven optimization},
year = {2024},
publisher = {JMLR.org},
booktitle = {Proceedings of the 41st International Conference on Machine Learning},
articleno = {441},
numpages = {19},
location = {Vienna, Austria},
series = {ICML'24}
}